

How to Sync Data Between Different Databases
Hi everyone! I’m Stanislav Bushuev, a Software Engineer at Semrush. In this article, I will share ideas on how to implement data synchronization across different types of databases. This is relevant in cases when, for instance, you are obliged to delete user data under General Data Protection Regulation (GDPR) or California Consumer Privacy Act (CCPA).
If you maintain a small product or an uncomplicated website, it doesn’t seem to be too much of a challenge to comply with these laws. Most likely, in such cases you can use one of the most common frameworks and store the user table in a popular database (MySQL or PostgreSQL). Basically, whenever you get a request to delete all user data, it’s easy to handle: you simply delete a row in the table, and it’s done. Here, we assume that everything is set up correctly, and the data in logs, error traces, backups, and places like that is automatically deleted or replaced, too.
In our case, however, the situation is a bit more complex. Since 2008, Semrush has created over 50 tools that are supported by dozens of developer teams. A few years ago, each team moved the code of their tools to a microservice. Microservices receive user data from a separate microservice that we call the user service.
Now that we have a centralized place for storing user data and multiple microservices that use the data, we are facing a challenge on how to keep them in sync.
Synchronization methods
There are several ways how a microservice can exchange data with the user service.
- From time to time, a microservice can send data to the user service via the REST API:
$ curl '<http://user-service.internal.net/api/v1/users/42>'
[
{
"id": 42,
"registration_date": "2015-03-08 01:00:00",
"email": "john@example.com",
"name": "John",
...Theoretically, we can send a full list of users, but it’s rather odd. There is no need to check user data often enough to send so many requests that it may seem like a DDoS attack.
2. Event-driven architecture is another approach to fix our issue. Here, we will have two entities: a message generator (so-called Publisher) and a Subscriber who reads the event feed (topic).
You can drop the subscriber entity and set all microservices to an endpoint API, which the user service would send requests to whenever a new event occurs. In this case, you will need to agree on API interaction protocols: REST, JSON-RPC, gRPC, GraphQL, OpenAPI, or whatever else is possible. You will also need to keep configuration files of the microservices where you send requests to. But most importantly you will need to figure out the following: what to do when a request doesn’t reach the microservice after several attempts?
Pros of this architecture:
- Databases get synced automatically and asynchronously.
- The user service load doesn’t increase too much, as we only add asynchronous event recording to the event feed.
- Various databases sync on their own, without involving the user service that is already overloaded.
Cons:
- A downside arising from the first pro: data exchanged between a user services and the rest of the microservices can be inconsistent.
- Lack of transactions that causes that only simple messages are generated.
- Messages in the queue can be repetitive.
In general, all the advantages and disadvantages listed above are rather relative and largely depend on your specific tasks. In my opinion, there are no universal solutions. I recommend reading more on the CAP theorem if this topic interests you.
Implementation of event-driven architecture: Pub/Sub case
Even though there are many alternatives (Kafka, RabbitMQ, etc.), our team chose the Pub/Sub Google Cloud solution. We already use Google Cloud, so it seemed easier to configure the Kafka and RabbitMQ.
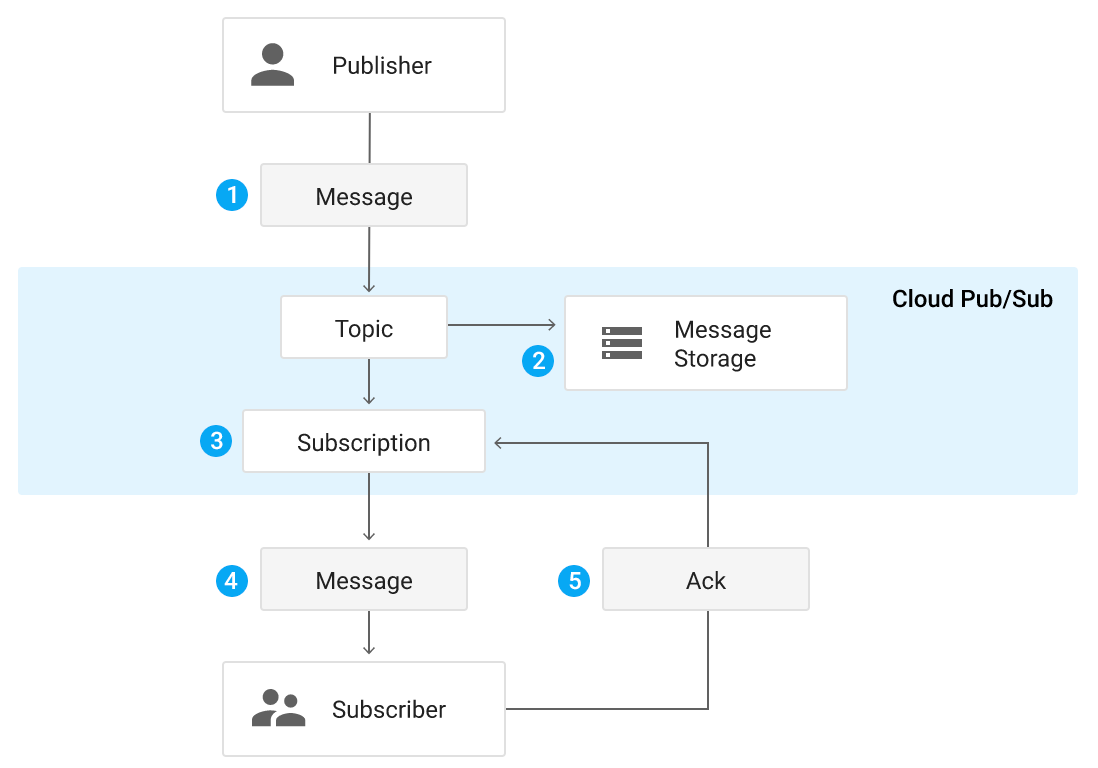
In our case, Publisher is the user service, and Subscriber is a microservice of the team working on a particular tool. There can be as many Subscribers (as well as Subscriptions) as you want. Considering that Semrush has a large number of tools and teams, the Subscriber queue is optimal for us, and this is why:
- Everyone reads the queue with the frequency that suits them.
- Once somebody adds an endpoint, the topic will be able to call it from then on whenever a message appears (if there is a need to get new messages instantly).
- Even less common options, such as rolling back the tool database from an old backup, don’t cause problems: you can just reread the messages from the topic. It’s worth mentioning, though, that you should consider the idempotency of requests, and perhaps start reading the topic from a specific passage.
- Subscriber provides the REST protocol, but to make development easier, there are also clients for various languages: Go, Java, Python, Node.js, C#, C++, PHP, and Ruby.
You can also use one topic with different messages. For instance, there are several types of messages available: change user, change user accesses, and so on.
Implementation Example
Create a topic and a subscriber:
gcloud pubsub topics create topic
gcloud pubsub subscriptions create subscription --topic=topicSee the documentation for details.
Create a user to read the topic:
gcloud iam service-accounts create SERVICE_ACCOUNT_ID \
--description="DESCRIPTION" \
--display-name="DISPLAY_NAME"
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="serviceAccount:SERVICE_ACCOUNT_ID@PROJECT_ID.iam.gserviceaccount.com" \
--role="pubsub.subscriber"
gcloud iam service-accounts keys create key-file \
--iam-account=sa-name@project-id.iam.gserviceaccount.comThe downloaded key in the JSON format must be saved and sent to the service. Don’t forget about keeping secrets though! My colleagues from the Security Team can tell you everything about it. If you find this topic useful, let me know in the comments, and I’ll elaborate on it in my next article.
A user for publishing messages is created in a similar way, except for the role: --role="pubsub.subscriber" → --role="pubsub.publisher".
As an example, let’s take one of our microservices written in Python and using Celery. There is a Protobuf schema for messages from the user service:
import json
import os
import celery
from google.cloud import pubsub_v1
from google.oauth2 import service_account
from user_pb2 import UserEventData
PUBSUB_SERVICE_ACCOUNT_INFO = json.loads(os.environ.get('PUBSUB_SERVICE_ACCOUNT', '{}'))
PUBSUB_PROJECT = 'your project'
PUBSUB_SUBSCRIBER = 'subscription'@celery.shared_task
def pubsub_synchronisation() -> None:
credentials = service_account.Credentials.from_service_account_info(
PUBSUB_SERVICE_ACCOUNT_INFO, scopes=['<https://www.googleapis.com/auth/pubsub>']
)
with pubsub_v1.SubscriberClient(credentials=credentials) as subscriber:
subscription_path = subscriber.subscription_path(PUBSUB_PROJECT, PUBSUB_SUBSCRIBER)
response = subscriber.pull(request={"subscription": subscription_path, "max_messages": 10000})
ack_ids, removed_user_ids = [], []
for msg in response.received_messages:
user_event_data = UserEventData()
user_event_data.ParseFromString(msg.message.data)
removed_user_ids.append(user_event_data.Id)
ack_ids.append(msg.ack_id)
# Here you can do everything with removed users :)
subscriber.acknowledge(request={"subscription": subscription_path, "ack_ids": ack_ids})Then we run the task once every five minutes, considering that deleting users is not such a common operation:
CELERY_BEAT_SCHEDULE = {
'pubsub_synchronisation': {
'task': 'tasks.pubsub_ubs_synchronisation',
'schedule': timedelta(minutes=5)
},Publishing messages to a topic using Python is implemented in a similar way. Use PublisherClient instead of SubscriberClient and call publish instead of pull.
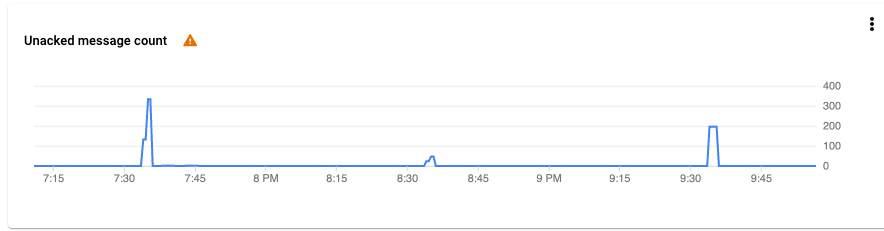
We have set up data synchronization that helps us delete user data and thus be compliant with GDPR/CCPA. Now let’s have a look at how this synchronization works. At 7:37, many accounts got deleted in the user service. Then at 7:40 the task to retrieve data from Topic was triggered. All tasks have been completed and the databases are now in sync.
In this article I walked you through two options on how you set up data synchronization and explained why the event-driven one works better for us. Your case can be similar or completely different, but I hope that this article will help you choose the solution for your needs.